
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 후기
- Python
- 함수
- 재귀함수
- 머신러닝
- 데이터분석
- numpy
- 사이킷런
- 기사
- 데이터사이언스 스쿨
- 데이터사이언티스트
- 파이썬
- 자연어처리
- TensorFlow
- 파이썬코딩도장
- 제로베이스 데이터사이언스
- 스크랩
- 카카오
- 아이펠
- Set
- 제어문
- NLP
- 코딩도장
- 클래스
- AIFFEL
- 추천시스템
- 딕셔너리
- AI
- 딥러닝
- 속성
- Today
- Total
뮤트 개발일지
AIFFEL 아이펠 35일차 본문
인간보다 퀴즈를 잘 푸는 인공지능
BERT 모델
Transformer Encoder 구조만을 활용한다. Layer는 12개 이상으로 늘리고, 파라미터 크기가 크긴 하지만 트랜스포머 모델과 기본적인 구조는 동일하다. BERT 모델은 Decoder가 없는 대신, 출력 모델이 Mask LM, NSP라는 2가지 모델을 해결하도록 되어 있다.
Mask LM
입력데이터가 '나는 <mask> 먹었다' 일 때, BERT 모델이 <mask>가 '밥'임을 맞출 수 있도록 하는 언어모델이다.
Next Sentence Prediction
입력데이터가 '나는 밥을 먹었다. <SEP> 그래서 지금 배가 부르다.'가 주어졌을 때 <SEP>을 경계로 좌우 두 문장이 순서대로 이어지는 문장이 맞는지 맞추는 문제이다. BERT 모델은 이 두 문장을 입력으로 받았을 때 첫 번째 바이트에서 NSP 결과값을 리턴한다.
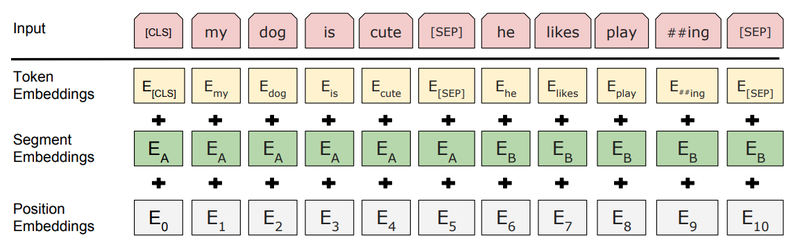
BERT 모델의 입력 부분을 보면, 텍스트 입력이 위 그림의 [Input]처럼 주어졌을 때, 실제로 모델에 입력되는 것은 Token, Segment, Position Embedding 3가지가 더해진 형태이다. 그리고 이후 layer normalization과 dropout이 추가된다.
Token Embedding
BERT는 텍스트의 tokenizer로 Word Piece model이라는 subword tokenizer를 사용한다. 문자단위로 임베딩하는 것이 기본이지만, 자주 등장하는 긴 길이의 subword도 하나의 단위로 만든다. 자주 등장하지 않는 단어는 다시 subword 단위로 쪼개진다. 이것은 자주 등장하지 않는 단어가 out-of-vocabulary,OOV 처리 되는 것을 방지한다. 그래서 최종적으로 Word Piece 모델의 각 임베딩이 입력된다.
Segment Embedding
기존 Transformer에 없는 임베딩이다. 각 단어가 어느 문장에 포함되는지 역할을 규정한다.
이해 안되는 BERT는 여기까지만 적고, 요즘 생각을 정리해보고자 한다.
요즘 점점 더 어려워지는 내용들을 보며.. 내가 제대로 하고 있는 건지 의문이 든다.
NLP는 내 길이 아니라는 생각에 가볍게 넘어가도, CV에 관련된 내용들도 두루뭉술, 대강 보고 넘어가는 느낌이 많이 든다. 취업 걱정도 되고, 이렇게 공부하다가는 이도저도 아닌 6개월이 되겠다 싶다. 그래서 EDA 스터디에 들어갔는데, 다음 주 화요일이 정식적인 첫 모임이 될 것 같아, 아직은 아리송하다. 노드도, 풀잎도, 어떤 내용도 완벽하게 이해했다!라는 기분이 들지 않아 매일이 찝찝한 상태이다. 이 와중에 끈질기게 붙잡고 계시는 분들도 계시고, 처음엔 파이썬 하나도 모르시던 분이 우수 노드에 뽑히시는 걸 보니 나는 자꾸 작아지고 초라해지는 것 같다. 그러나 언제까지 무기력하게만 있을 수는 없는 법. 어떻게 해결해야 할까.
지금까지 생각한 바로는
1. 노드와 익스 제출은 밀리지 않는다.
2. 일과시간 이후에는 EDA 공부를 한다.
3. 주말은 잘 이해가지 않았던 부분과 EDA를 중점적으로 공부한다.
4. 2월 마지막 주는 방학이다. 이 때를 틈타 혼공머를 쭉 돌려야겠다.
그리고 가고 싶은 회사 리스트업을 해봐야겠다. 그러면 좀 더 동기부여가 되지 않을까.
몸도 마음도 벌써 많이 지친 35일차.. 너무 일찍 지쳐버린 건 아닐까 걱정되지만 좀 더 힘을 내보자.
'AIFFEL' 카테고리의 다른 글
| AIFFEL 아이펠 37일차 (0) | 2022.02.21 |
|---|---|
| AIFFEL 아이펠 36일차 (0) | 2022.02.18 |
| AIFFEL 아이펠 34일차 (0) | 2022.02.17 |
| AIFFEL 아이펠 33일차 (0) | 2022.02.17 |
| AIFFEL 아이펠 32일차 (0) | 2022.02.16 |

