
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 속성
- AI
- 제어문
- 딥러닝
- 아이펠
- 코딩도장
- 스크랩
- 자연어처리
- 추천시스템
- 데이터사이언티스트
- AIFFEL
- 기사
- TensorFlow
- 딕셔너리
- 클래스
- 데이터사이언스 스쿨
- 카카오
- numpy
- 제로베이스 데이터사이언스
- 함수
- Set
- 사이킷런
- 머신러닝
- 파이썬
- Python
- 후기
- 파이썬코딩도장
- NLP
- 데이터분석
- 재귀함수
- Today
- Total
뮤트 개발일지
AIFFEL 아이펠 28일차 본문
인공지능으로 세상에 없던 새로운 패션 만들기
생성 모델링 Generative Modeling
판별 모델: 입력된 데이터셋을 특정 기준에 따라 분류하거나, 특정 값을 맞추는 모델
생성 모델: 학습한 데이터셋과 비슷하면서도 기존에는 없던 새로운 데이터셋을 생성하는 모델
Fashion MNIST 데이터를 사용할 예정
데이터셋의 이미지 크기: 28 * 28
데이터셋의 이미지 개수: 70,000장(training data 60,000 / test data 10,000)
카테고리:
0: T-shrit/top
1: Trouser
2: Pullover
3: Dress
4: Coat
5: Sandal
6: Shirt
7: Sneaker
8: Bag
9: Ankle boot
데이터셋 가져오기
tf.keras에 데이터셋이 들어가 있기 때문에 인터넷에서 다운받을 필요가 없다.
import os
import glob
import time
import PIL
import imageio
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from IPython import display
import matplotlib.pyplot as plt
%matplotlib inline라벨이 필요없어(train_y, test_y) _로 해당 데이터를 무시 처리해준다.
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_x, _), (test_x, _) = fashion_mnist.load_data()-1 ~ 1 사이로 정규화 해준다.
train_x = (train_x - 127.5) / 127.5흑백 이미지로 채널이 1이다. shape에 1을 추가해준다.
train_x = train_x.reshape(train_x.shape[0], 28, 28, 1).astype('float32')
train_x.shape
>>> (60000, 28, 28, 1)이미지 확인하기
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(train_x[i].reshape(28, 28), cmap='gray')
plt.title(f'index: {i}')
plt.axis('off')
plt.show()
BUFFER_SIZE = 60000
BATCH_SIZE = 256train_dataset = tf.data.Dataset.from_tensor_slices(train_x).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)BATCH_SIZE: 한 번에 학습할 데이터의 양
from_tensor_slices(): 리스트, 넘파이, 텐서플로우의 텐서 자료형에서 데이터셋을 만들 수 있다.
위의 코드 설명 => train_x라는 넘파이 배열형 자료를 섞고, 이를 배치 사이즈에 따라 나눈다.
데이터가 잘 섞이게 하기 위해서는 버퍼 사이즈를 총 데이터 사이즈와 같거나 크게 설정하는 것이 좋다.
GAN(Generative Adversarial Network)
생성모델 중 하나이다.
생성자Generator: 의미 없는 랜덤 노이즈로부터 신경망에서의 연산을 통해 이미지 형상의 벡터를 생성한다. 무에서 유를 창조하는 것과 같은 역할을 한다.
판별자Discriminator: 기존에 있던 진짜 이미지와 생성자가 만들어낸 이미지를 입력받아 각 이미지가 진짜인지, 가짜인지에 대한 판단 정도를 실수값으로 출력한다.
이러한 생성자와 판별자가 서로 경쟁하듯이 이루어져 있다.
생성자 구현하기
우리가 다뤄볼 모델은 DCGAN(Deep Convolution GAN)이다.
def make_generator_model():
# Start
model = tf.keras.Sequential()
# First: Dense layer
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# Second: Reshape layer
model.add(layers.Reshape((7, 7, 256)))
# Third: Conv2DTranspose layer
model.add(layers.Conv2DTranspose(128, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# Fourth: Conv2DTranspose layer
model.add(layers.Conv2DTranspose(64, kernel_size=(5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# Fifth: Conv2DTranspose layer
model.add(layers.Conv2DTranspose(1, kernel_size=(5, 5), strides=(2, 2), padding='same', use_bias=False, \
activation='tanh'))
return modeltf.keras.Sequential()로 모델을 시작하고 레이어를 쌓아준다.
Conv2DTranspose 레이어는 이미지 사이즈를 넓혀주는 층이다. 이 모델에서는 3번의 Conv2DTranspose층을 이용해 (7, 7, 256) -> (14, 14, 64) -> (28, 28, 1) 순으로 이미지를 키운다. 여기서 최종 사이즈는 우리가 준비했던 데이터셋과 형상이 동일하다.
BatchNormalization 레이어는 신경망의 가중치가 폭발하지 않도록 가중치 값을 정규화 해준다.
중간층들의 활성화 함수는 모두 LeakyReLU를 사용했다.
단, 마지막 층에는 활성화 함수로 tanh를 사용했는데, 이는 우리가 -1 ~ 1 사이의 값으로 픽셀을 정규화시켰던 데이터셋과 동일하게 하기 위해서이다.
generator = make_generator_model()
generator.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12544) 1254400
_________________________________________________________________
batch_normalization (BatchNo (None, 12544) 50176
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 12544) 0
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 7, 7, 128) 819200
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 204800
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 1600
=================================================================
Total params: 2,330,944
Trainable params: 2,305,472
Non-trainable params: 25,472
_________________________________________________________________tf.random.normal: 가우시안 분포에서 뽑아낸 랜덤 벡터로 이루어진 노이즈 벡터를 만들 수 있다.
noise = tf.random.normal([1, 100])생성자 모델에 입력값으로 노이즈를 넣고 바로 모델을 호출하면 간단히 결과 이미지가 생성된다.
단, 지금은 학습하는 중이 아니기 때문에 training=False를 설정한다. Batch Normalization 레이어는 훈련 시기와 추론 시기의 행동이 다르기 때문에 training=False를 주어야 올바른 결과를 얻을 수 있다.
generated_image = generator(noise, training=False)
generated_image.shape
>>> TensorShape([1, 28, 28, 1])이미지 시각화
matplotlib은 2차원 이미지만 보여줄 수 있으므로 0번, 3번째 축의 인덱스를 0으로 설정하여 (28, 28)의 이미지를 꺼낼 수 있도록 한다.
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
plt.colorbar()
plt.show()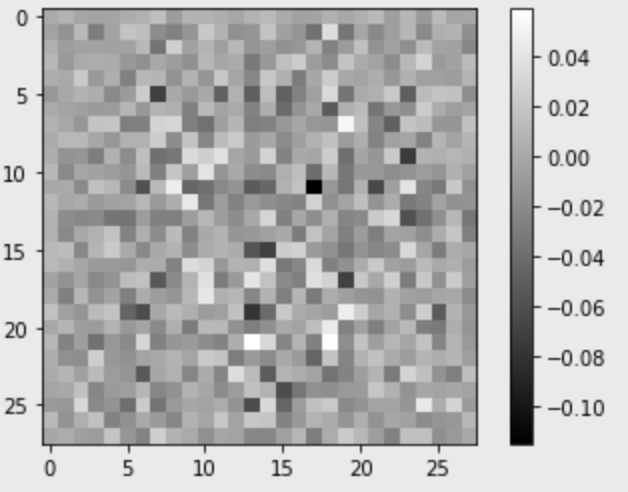
-1 ~ 1 사이의 값으로 이미지가 만들어졌다. 아직은 모델이 전혀 학습하지 않은 상태로 의미 없는 노이즈같은 이미지가 생성됐다.
판별자 구현하기
def make_discriminator_model():
# Start
model = tf.keras.Sequential()
# First: Conv2D Layer
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
# Second: Conv2D Layer
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
# Third: Flatten Layer
model.add(layers.Flatten())
# Fourth: Dense Layer
model.add(layers.Dense(1))
return modelConv2D 층으로 이미지의 크기를 줄여간다.
첫번째 Conv2D 층에서 입력된 [28, 28, 1] 사이즈의 이미지는 (28, 28, 1) -> (14, 14, 64) -> (7, 7, 128)까지 줄어든다.
Flatten 층으로 3차원 이미지를 1차원으로 펴서 7*7*128 = 6272, 즉 (1, 6272) 형상의 벡터로 변환한다.
마지막 Dense Layer를 거쳐 단 하나의 값을 출력하게 된다.
discriminator = make_discriminator_model()
discriminator.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 64) 1664
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 128) 204928
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 6273
=================================================================
Total params: 212,865
Trainable params: 212,865
Non-trainable params: 0
_________________________________________________________________아까 생성한 가짜 이미지를 여기에 입력하면,
decision = discriminator(generated_image, training=False)
decision<tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[-0.00027368]], dtype=float32)>아직은 아무런 의미없는 값일 것
모델을 학습시키기 위해서는 손실함수와 최적화함수가 필요하다.
손실함수 loss function
GAN은 손실함수로 교차 엔트로피Cross Entropy를 사용한다.
교차 엔트로피: 점점 가까워지기를 원하는 두 값이 얼마나 큰 차이가 나는지 정량적으로 계산할 때 많이 쓰인다.
특히 판별자는 한 개의 이미지가 진짜인지 가짜인지 나타내는 2개 클래스 간 분류 문제를 풀어야하므로 이진 교차 엔트로피binary cross entropy를 사용할 것이다.
진짜 이미지에 대한 라벨을 1, 가짜 이미지에 대한 라벨을 0으로 두었을 때, 각각의 손실함수를 이용해 정량적으로 달성해야 하는 목표는 다음과 같다.
- 생성자: 판별자가 가짜 이미지에 대해 판별한 값이 1에 가까워지는 것
- 판별자: 진짜 이미지 판별값은 1에, 가짜 이미지에 대한 판별값은 0에 가까워지는 것
=> 생성자든 판별자든, 결국 손실함수에 들어가는 값은 모두 판별자의 판별값이 된다.
그런데 판별자 모델의 맨 마지막 레이어에는 값을 정규화시키는 활성화 함수가 없다. 즉, 판별자가 출력하는 값은 범위가 정해져있지 않아 모든 실수값을 가질 수 있다. 그러나 BinaryCrossEntropy클래스는 기본적으로 본인에게 들어오는 인풋값이 0~1 사이에 분포하는 확률값이라고 가정한다. 따라서 from_logits을 True로 설정해주어야 BinaryCrossEntropy에 입력된 값을 함수 내부의 시그모이드 함수를 사용해 0~1 사이의 값으로 정규화한 후 알맞게 계산할 수 있다.
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)cross_entropy를 활용해 계산할 loss들은 fake_output과 real_output 두 가지를 활용한다.
- fake_output: 생성자가 생성한 가짜 이미지를 판별자에 입력시켜서 판별된 값
- real_output: 기존에 있던 진짜 이미지를 판별자에 입력시켜서 판별된 값
tf.ones_like(), tf.zeros_like()
특정 벡터와 동일한 크기면서 값은 1 또는 0으로 가득 채워진 벡터를 만들고 싶을 때 사용한다.
generator_loss는 fake_output이 1에 가까워지기를 바라므로, 아래와 같이 tf.ones_like와의 교차 엔트로피값을 계산한다.
즉, cross_entropy(tf.ones_like(fake_output), fake_output) 값은 fake_outpur이 진짜 이미지를 의미하는 1에 가까울수록 작은 값을 가진다.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)반면, discirminator_loss는 real_output 값은 1에 가까워지기를, fake_output 값은 0에 가까워지기를 바라기 때문에 두 loss를 모두 계산한다. real_output은 1로 채워진 벡터와, fake_output은 0으로 채워진 벡터와 비교한다.
최종 discriminator_loss는 이 둘을 더한 값이다.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_lossdiscriminator accuracy
판별자가 얼마나 정확히 판별하는지의 정확도를 계산하는 것도 중요하다. 특히 두 정확도를 따로 계산해서 비교해보는 것이 유용하다.
만약 판별자가 real output, fake output을 정확도가 1.0에 가까울 정도로 정확하게 판별해 낸다면 좋은 것일까? 아니다. 이 경우 생성자가 만들어내는 fake output이 real output과 차이가 많이 나기 때문에 판별자가 너무 쉽게 판별하고 있다는 뜻이기 때문이다. 그래서 초반에서는 정확도가 1.0에 가깝다가, 서서히 낮아져 0.5에 가까워지는 것이 이상적이다. fake accuracy가 1.0에 가깝다면 아직 생성자가 판별자를 충분히 잘 속이지 못하고 있다는 뜻!
def discriminator_accuracy(real_output, fake_output):
real_accuracy = tf.reduce_mean(tf.cast(tf.math.greater_equal(real_output, tf.constant([0.5])), tf.float32))
fake_accuracy = tf.reduce_mean(tf.cast(tf.math.less(fake_output, tf.constant([0.5])), tf.float32))
return real_accuracy, fake_accuracy예) real_output = tf.Tensor([0.2, 0.4, 0.7, 0.9]) 라면
(1) tf.math.greater_equal(real_output, tf.constant([0.5]): real_output의 각 원소가 0.5 이상인지 true, false로 판별
=> tf.Tensor([False, False, True, True])
(2) tf.cast( (1), tf.float32): (1)의 결과가 True이면, 1.0, False이면 0.0으로 변환
=> tf.Tensor([0.0, 0.0, 1.0, 1.0])
(3) tf.reduce_mean( (2)): (2)의 결과를 평균내어 이번 배치의 정확도 계산
=> 0.5
최적화 함수 optimizer
Adam 최적화 기법을 사용할 것
생성자와 판별자는 따로 학습을 진행하는 개별 네트워크이기 때문에 optimizer를 따로 만들어주어야 한다.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)학습이 어떻게 진행되는지 확인하기 위해 생성자가 생성한 샘플을 확인할 것
샘플은 한 번에 16장 생성
생성할 샘플은 같은 노이즈로 생성해야 그에 대한 진전 과정을 확인할 수 있기 때문에, 고정된 seed 노이즈를 만들어야 한다.
100차원의 노이즈를 총 16개, (16, 100) 형상의 벡터를 만들 것
noise_dim = 100
num_examples_to_generate = 16
seed = tf.random.normal([num_examples_to_generate, noise_dim])
seed.shape
>>> TensorShape([16, 100])
훈련과정 설계
@tf.function
def train_step(images): #(1) 입력데이터
noise = tf.random.normal([BATCH_SIZE, noise_dim]) #(2) 생성자 입력 노이즈
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: #(3) tf.GradientTape() 오픈
generated_images = generator(noise, training=True) #(4) generated_images 생성
#(5) discriminator 판별
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
#(6) loss 계산
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
#(7) accuracy 계산
real_accuracy, fake_accuracy = discriminator_accuracy(real_output, fake_output)
#(8) gradient 계산
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
#(9) 모델 학습
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss, real_accuracy, fake_accuracy #(10) 리턴값- 입력 데이터: 진짜 이미지 역할을 할 이미지 한 세트를 입력으로 받는다.
- 생성자 입력 노이즈: generator가 가짜 이미지를 생성하기 위한 노이즈를 이미지 한 세트와 같은 크기인 BATCH_SIZE만큼 생성
- tf.GradientTape(): 가중치 갱신을 위한 Gradient를 자동 미분으로 계산하기 위해 with 구문 열기
- generated_images 생성: generator가 noise를 입력받은 후 generated_images 생성
- discriminator 판별: discriminator가 진짜 이미지인 images와 가짜 이미지인 generated_images를 입력받은 후 real_output, fake_output 출력
- loss 계산: fake_output, real_output으로 discriminator의 정확도 계산
- gradient 계산: gen_tape와 disc_tape를 활용해 gradient 자동으로 계산
- 모델 학습: 계산된 gradient를 optimizer에 입력해 가중치 갱신
- 리턴값: 이전 단계에 계산된 loss와 accuracy 리턴
이렇게 한 단계씩 학습할 train_step과 함께 일정 간격으로 학습 현황을 볼 수 있는 샘플을 생성하는 함수 만들기
고정된 seed에 대한 결과물이 얼마나 나아지고 있는지 확인할 수 있다.
def generate_and_save_images(model, epoch, it, sample_seeds):
predictions = model(sample_seeds, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
plt.savefig('{}/aiffel/dcgan_newimage/fashion/generated_samples/sample_epoch_{:04d}_iter_{:03d}.png'
.format(os.getenv('HOME'), epoch, it))
plt.show()from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 15, 6 # matlab 차트의 기본 크기를 15,6으로 지정해 줍니다.
def draw_train_history(history, epoch):
# summarize history for loss
plt.subplot(211)
plt.plot(history['gen_loss'])
plt.plot(history['disc_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('batch iters')
plt.legend(['gen_loss', 'disc_loss'], loc='upper left')
# summarize history for accuracy
plt.subplot(212)
plt.plot(history['fake_accuracy'])
plt.plot(history['real_accuracy'])
plt.title('discriminator accuracy')
plt.ylabel('accuracy')
plt.xlabel('batch iters')
plt.legend(['fake_accuracy', 'real_accuracy'], loc='upper left')
# training_history 디렉토리에 epoch별로 그래프를 이미지 파일로 저장합니다.
plt.savefig('{}/aiffel/dcgan_newimage/fashion/training_history/train_history_{:04d}.png'
.format(os.getenv('HOME'), epoch))
plt.show()정기적으로 모델을 저장하는 checkpoint를 만든다.
tf.train.Checkpoint를 활용하면 매번 모델을 직접 저장해주지 않아도 코드 한 줄로 빠르고 편하게 버전 관리를 할 수 있다.
checkpoint에는 optimize와 생성자와 판별자가 학습한 모델 가중치를 저장한다.
checkpoint_dir = os.getenv('HOME')+'/aiffel/dcgan_newimage/fashion/training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
def train(dataset, epochs, save_every):
start = time.time()
history = {'gen_loss':[], 'disc_loss':[], 'real_accuracy':[], 'fake_accuracy':[]}
for epoch in range(epochs):
epoch_start = time.time()
for it, image_batch in enumerate(dataset):
gen_loss, disc_loss, real_accuracy, fake_accuracy = train_step(image_batch)
history['gen_loss'].append(gen_loss)
history['disc_loss'].append(disc_loss)
history['real_accuracy'].append(real_accuracy)
history['fake_accuracy'].append(fake_accuracy)
if it % 50 == 0:
display.clear_output(wait=True)
generate_and_save_images(generator, epoch+1, it+1, seed)
print('Epoch {} | iter {}'.format(epoch+1, it+1))
print('Time for epoch {} : {} sec'.format(epoch+1, int(time.time()-epoch_start)))
if (epoch + 1) % save_every == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
display.clear_output(wait=True)
generate_and_save_images(generator, epochs, it, seed)
print('Time for training : {} sec'.format(int(time.time()-start)))
draw_train_history(history, epoch)save_every = 5
EPOCHS = 50
# 사용가능한 GPU 디바이스 확인
tf.config.list_physical_devices("GPU")%%time
train(train_dataset, EPOCHS, save_every)
# 학습과정의 loss, accuracy 그래프 이미지 파일이 ~/aiffel/dcgan_newimage/fashion/training_history 경로에 생성되고 있으니
# 진행 과정을 수시로 확인해 보시길 권합니다.학습 과정 시각화하기
생성한 샘플 이미지들을 합쳐 gif 파일로 만들어보자.
gif 파일은 imageio 라이브러리를 활용해 만들 수 있다. imageio.get_writer을 활용해 파일을 열고, append_data로 이미지를 하나씩 붙여나가는 방식이다.
anim_file = os.getenv('HOME')+'/aiffel/dcgan_newimage/fashion/fashion_mnist_dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('{}/aiffel/dcgan_newimage/fashion/generated_samples/sample*.png'.format(os.getenv('HOME')))
filenames = sorted(filenames)
last = -1
for i, filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
!ls -l ~/aiffel/dcgan_newimage/fashion/fashion_mnist_dcgan.gif
'AIFFEL' 카테고리의 다른 글
| AIFFEL 아이펠 30일차 (0) | 2022.02.11 |
|---|---|
| AIFFEL 아이펠 29일차 (0) | 2022.02.10 |
| AIFFEL 아이펠 27일차 (0) | 2022.02.10 |
| AIFFEL 아이펠 26일차 (0) | 2022.02.04 |
| AIFFEL 아이펠 25일차 (0) | 2022.02.03 |



