
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- TensorFlow
- AI
- 클래스
- 코딩도장
- AIFFEL
- 추천시스템
- numpy
- Set
- 카카오
- 데이터분석
- 재귀함수
- 기사
- Python
- 후기
- NLP
- 딕셔너리
- 스크랩
- 딥러닝
- 제로베이스 데이터사이언스
- 데이터사이언스 스쿨
- 데이터사이언티스트
- 사이킷런
- 아이펠
- 파이썬
- 파이썬코딩도장
- 함수
- 머신러닝
- 속성
- 제어문
- 자연어처리
- Today
- Total
뮤트 개발일지
AIFFEL 아이펠 30일차 본문
어제 오른 내 주식, 과연 내일은?
시계열(Time-Series): 시간 순서대로 발생한 데이터의 수열
미래를 예측하기 위해서는 두 가지 조건이 필요하다.
- 과거 데이터에 일정한 패턴이 있다.
- 과거의 패턴은 미래에도 동일하게 반복될 것이다.
=> 안정적(Stationary) 데이터에 대해서만 미래 예측이 가능하다.
안정적인 시계열에서 시간의 추이와 관계없이 일정해야 하는 통계적 특성: 평균, 분산, 공분산(정확히는 자기공분산autocovariance)
용어 정리한 글
https://destrudo.tistory.com/15
공분산(Covariance)과 상관계수(Correlation)
확률변수X가 있을때 우리가 흔히 이 분포를 나타낼때 쓰는것이 첫번째로 평균이고 두번째로 분산이다. 평균으로써 분포의 중간부분을 알아내고 분산으로써 분포가 얼마나 퍼져있는지 알아낸다
destrudo.tistory.com
시계열 데이터 사례분석
(1) Daily Minimum Temperatures in Melbourne
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
dataset_filepath = os.getenv('HOME')+'/aiffel/stock_prediction/data/daily-min-temperatures.csv'
df = pd.read_csv(dataset_filepath)
print(type(df))
df.head()<class 'pandas.core.frame.DataFrame'>
Date 컬럼을 인덱스로 바꾼다.
# 이번에는 Date를 index_col로 지정해 주었습니다.
df = pd.read_csv(dataset_filepath, index_col='Date', parse_dates=True)
print(type(df))
df.head()<class 'pandas.core.frame.DataFrame'>
데이터타입이 DataFrame으로 나온다. 우리가 찾은 시계열 데이터는 여기에 있다.
ts1 = df['Temp'] # 우선은 데이터 확인용이니 time series 의 이니셜을 따서 'ts'라고 이름 붙여줍시다!
print(type(ts1))
ts1.head()<class 'pandas.core.series.Series'>
Date
1981-01-01 20.7
1981-01-02 17.9
1981-01-03 18.8
1981-01-04 14.6
1981-01-05 15.8
Name: Temp, dtype: float64시각화를 통해 시계열 데이터의 안정성을 확인해보자.
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 13, 6 # matlab 차트의 기본 크기를 13, 6으로 지정해 줍니다.
# 시계열(time series) 데이터를 차트로 그려 봅시다. 특별히 더 가공하지 않아도 잘 그려집니다.
plt.plot(ts1)
결측치 확인
ts1[ts1.isna()] # 시계열(Time Series)에서 결측치가 있는 부분만 Series로 출력합니다.Series([], Name: Temp, dtype: float64)다행히 결측치는 없다. 만약 결측치가 있다면, 1. 결측치를 모두 삭제하거나, 2. 결측치 양옆의 값을 이용해 적절히 보간하는 방법이 있다.
# 결측치가 있다면 이를 보간합니다. 보간 기준은 time을 선택합니다.
ts1=ts1.interpolate(method='time')
# 보간 이후 결측치(NaN) 유무를 다시 확인합니다.
print(ts1[ts1.isna()])
# 다시 그래프를 확인해봅시다!
plt.plot(ts1)
조금 더 명확하게 보기 위해 구간 통계치(Rolling Statistics)를 시각화 해보자.
현재 타임 스텝부터 window에 주어진 타임 스텝 이전 사이 구간의 평균(rolling mean, 이동평균)과 표준편차(rolling std, 이동표준편차)를 원본 시계열과 함께 시각화해보자.
* 여기서 이동 평균이란 무엇인가
https://www.econowide.com/3544
이동평균이란 무엇인가! 이동평균 개념과 종류 및 이동평균 공식을 이용한 이동평균계산방법
본 글은 이동평균이란 무엇인지 Moving Average (MA) 이동평균 개념과 종류 및 이동평균 공식을 이용한 이동평균계산방법을 설명합니다. 이동평균 (MA, Moving Average) 계산법을 이용해 산출된 이동평균
www.econowide.com
def plot_rolling_statistics(timeseries, window=12):
rolmean = timeseries.rolling(window=window).mean() # 이동평균 시계열
rolstd = timeseries.rolling(window=window).std() # 이동표준편차 시계열
# 원본시계열, 이동평균, 이동표준편차를 plot으로 시각화해 본다.
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label='Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)plot_rolling_statistics(ts1, window=12)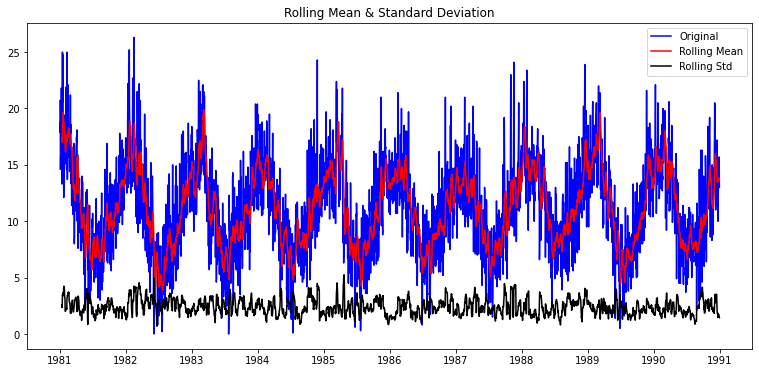
통계적인 접근은 아래에서 확인하고, 다른 데이터의 패턴과 비교를 먼저 해보자.
(2) International airline passengers
dataset_filepath = os.getenv('HOME')+'/aiffel/stock_prediction/data/airline-passengers.csv'
df = pd.read_csv(dataset_filepath, index_col='Month', parse_dates=True).fillna(0)
print(type(df))
df.head()<class 'pandas.core.frame.DataFrame'>
ts2 = df['Passengers']
plt.plot(ts2)
plot_rolling_statistics(ts2, window=12)
시간의 추이에 따라 평균과 분산이 증가하는 패턴을 보이면 적어도 안정적이지는 않다고 정성적인 결론을 내릴 수 있다.
아래에서 불안정적인 시계열 데이터에 대한 분석 기법을 다뤄보도록 할 것
Stationary 여부를 체크하는 통계적인 방법
ADF Test(Augmented Dickey-Fuller Test): 시계열 데이터의 안정성을 테스트하는 방법으로, 주어진 시계열 데이터가 안정적이 않다는 귀무가설(Null Hypothesis)을 세운 후, 통계적 가설 검증 과정을 통해 이 귀무가설이 기각될 경우 이 시계열 데이터가 안정적이라는 대립가설(Alternative Hypothesis)를 채택하는 방법이다.
statsmodels 패키지에서 제공하는 adfuller 메서드를 이용해 주어진 timeseries에 대한 ADF Test를 수행하는 코드
from statsmodels.tsa.stattools import adfuller
def augmented_dickey_fuller_test(timeseries):
# statsmodels 패키지에서 제공하는 adfuller 메서드를 호출합니다.
dftest = adfuller(timeseries, autolag='AIC')
# adfuller 메서드가 리턴한 결과를 정리하여 출력합니다.
print('Results of Dickey-Fuller Test:')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)' % key] = value
print(dfoutput)augmented_dickey_fuller_test(ts1)Results of Dickey-Fuller Test:
Test Statistic -4.444805
p-value 0.000247
#Lags Used 20.000000
Number of Observations Used 3629.000000
Critical Value (1%) -3.432153
Critical Value (5%) -2.862337
Critical Value (10%) -2.567194
dtype: float64=> ts1(Daily Minimum Temperatures in Melbourne)시계열이 안정적이지 않다는 귀무가설은 p-value가 0에 가깝게 나와 이 귀무가설은 기각되고, 이 시계열이 안정적 시계열이라는 대립가설이 채택된다.
augmented_dickey_fuller_test(ts2)Results of Dickey-Fuller Test:
Test Statistic 0.815369
p-value 0.991880
#Lags Used 13.000000
Number of Observations Used 130.000000
Critical Value (1%) -3.481682
Critical Value (5%) -2.884042
Critical Value (10%) -2.578770
dtype: float64=> ts2(International airline passengers) 시계열이 안정적이지 않다는 귀무가설은 p-value가 1에 가깝게 나와, '주어진 시계열 데이터가 안정적이지 않다'는 직접적 증거는 아니지만, 귀무가설을 기각할 수 없게 되었으므로, 안정적 시계열이라고 말할 수는 없다.
Stationayr하게 만드는 방법
방법1: 정성적인 분석을 통해 보다 안정적인 특성을 가지도록 기존의 시계열 데이터를 가공/변형하는 시도
방법2: 시계열 분해(Time series decomposition) 기법 적용
방법1: 보다 안정적인 시계열로 가공하기
1-1. 로그함수로 변환
ts_log = np.log(ts2)
plt.plot(ts_log)
augmented_dickey_fuller_test(ts_log)Results of Dickey-Fuller Test:
Test Statistic -1.717017
p-value 0.422367
#Lags Used 13.000000
Number of Observations Used 130.000000
Critical Value (1%) -3.481682
Critical Value (5%) -2.884042
Critical Value (10%) -2.578770
dtype: float64p-value가 절반이상 줄어든 것을 확인할 수 있다. 그러나 평균이 계속 높아지기 때문에 문제는 남아있다.
1-2. Moving average 제거 - 추세Trend 상쇄하기
추세trend: 시간 추이에 따라 나타나는 평균값 변화
이 변화량을 제거하기 위해 moving average, 즉 rolling mean을 구해 ts_log에서 빼주면?
moving_avg = ts_log.rolling(window=12).mean() # moving average구하기
plt.plot(ts_log)
plt.plot(moving_avg, color='red')
ts_log_moving_avg = ts_log - moving_avg # 변화량 제거
ts_log_moving_avg.head(15)Month
1949-01-01 NaN
1949-02-01 NaN
1949-03-01 NaN
1949-04-01 NaN
1949-05-01 NaN
1949-06-01 NaN
1949-07-01 NaN
1949-08-01 NaN
1949-09-01 NaN
1949-10-01 NaN
1949-11-01 NaN
1949-12-01 -0.065494
1950-01-01 -0.093449
1950-02-01 -0.007566
1950-03-01 0.099416
Name: Passengers, dtype: float64결측치를 제거한다.
ts_log_moving_avg.dropna(inplace=True)
ts_log_moving_avg.head(15)Month
1949-12-01 -0.065494
1950-01-01 -0.093449
1950-02-01 -0.007566
1950-03-01 0.099416
1950-04-01 0.052142
1950-05-01 -0.027529
1950-06-01 0.139881
1950-07-01 0.260184
1950-08-01 0.248635
1950-09-01 0.162937
1950-10-01 -0.018578
1950-11-01 -0.180379
1950-12-01 0.010818
1951-01-01 0.026593
1951-02-01 0.045965
Name: Passengers, dtype: float64plot_rolling_statistics(ts_log_moving_avg)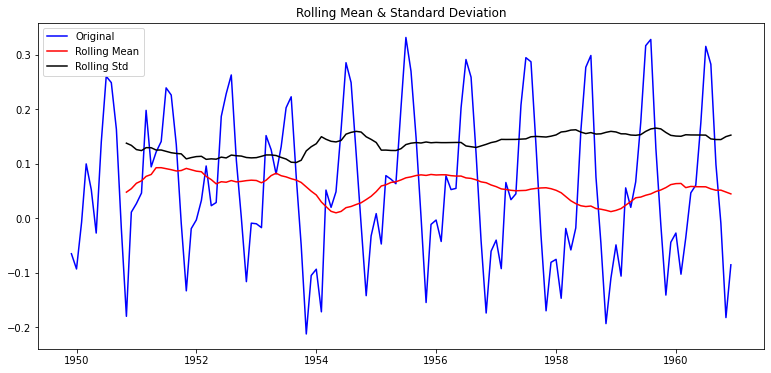
augmented_dickey_fuller_test(ts_log_moving_avg)Results of Dickey-Fuller Test:
Test Statistic -3.162908
p-value 0.022235
#Lags Used 13.000000
Number of Observations Used 119.000000
Critical Value (1%) -3.486535
Critical Value (5%) -2.886151
Critical Value (10%) -2.579896
dtype: float64p-value가 0.02 수준이 되었다.
여기서 중요한 점은 window=12로 잘 지정해줘야 한다는 것
1-3. 차분(Differencing) - 계절성(Seasonality) 상쇄하기
패턴이 파악되지 않는 주기적 변화는 예측에 방해가 되는 불안정성 요소이다. 이런 계절적, 주기적 패턴을 계절성이라고 한다.
차분: 시계열을 한 스텝 앞으로 이동한 시계열을 원래 시계열에 빼주는 방법. '남은 것 = 현재 스텝 값 - 직전 스텝 값'이 되어 정확히 이번 스텝에서 발생한 변화량을 의미하게 된다.
이동한 시계열과 원본 시계열
ts_log_moving_avg_shift = ts_log_moving_avg.shift()
plt.plot(ts_log_moving_avg, color='blue')
plt.plot(ts_log_moving_avg_shift, color='green')
원본 시계열에서 이동한 시계열을 빼준 그래프
ts_log_moving_avg_diff = ts_log_moving_avg - ts_log_moving_avg_shift
ts_log_moving_avg_diff.dropna(inplace=True)
plt.plot(ts_log_moving_avg_diff)
plot_rolling_statistics(ts_log_moving_avg_diff)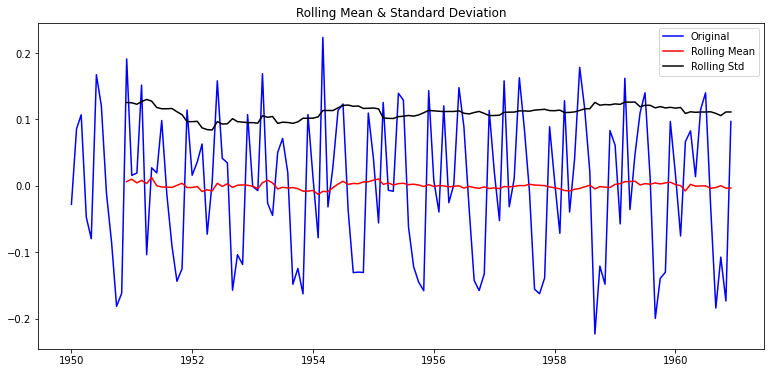
augmented_dickey_fuller_test(ts_log_moving_avg_diff)Results of Dickey-Fuller Test:
Test Statistic -3.912981
p-value 0.001941
#Lags Used 13.000000
Number of Observations Used 118.000000
Critical Value (1%) -3.487022
Critical Value (5%) -2.886363
Critical Value (10%) -2.580009
dtype: float64p-value가 약 0.22에서 1/10 줄어든 약 0.0019가 되었다.
방법2: 시계열 분해
statsmodels 라이브러리 안에 있는 seasonal_decompose 메소드를 통해 시계열 안에 존재하는 trend, seasonality를 직접 분리할 수 있다. 이 기능을 사용하면 우리가 위해서 직접 수행한 moving average 제거, differencing 등을 거치지 않아도 된다.
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(ts_log)
trend = decomposition.trend # 추세(시간 추이에 따라 나타나는 평균값 변화 )
seasonal = decomposition.seasonal # 계절성(패턴이 파악되지 않은 주기적 변화)
residual = decomposition.resid # 원본(로그변환한) - 추세 - 계절성
plt.rcParams["figure.figsize"] = (11,6)
plt.subplot(411)
plt.plot(ts_log, label='Original')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(trend, label='Trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(seasonal,label='Seasonality')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(residual, label='Residuals')
plt.legend(loc='best')
plt.tight_layout()
=> orignal에서 trend와 seasonality를 제거하고 난 나머지가 residual. 다시말해, trend + seasonality + residual = original이 성립
plt.rcParams["figure.figsize"] = (13,6)
plot_rolling_statistics(residual)
residual.dropna(inplace=True)
augmented_dickey_fuller_test(residual)Results of Dickey-Fuller Test:
Test Statistic -6.332387e+00
p-value 2.885059e-08
#Lags Used 9.000000e+00
Number of Observations Used 1.220000e+02
Critical Value (1%) -3.485122e+00
Critical Value (5%) -2.885538e+00
Critical Value (10%) -2.579569e+00
dtype: float64압도적으로 낮은 p-value를 보여준다.
ARIMA 모델
: AR(autoregressive) + I(integrated) + MA(moving average), 시계열 데이터 예측 모델을 자동으로 만들 수 있다.
(1) AR(자기회귀): 과거 값들에 대한 회귀로 미래 값을 예측하는 방법
(2) MA(이동평균): 최근의 증감 패턴을 지속할 것이라고 보는 관점
(3) I(차분누적)
ARIMA의 모수
- p: 자기회귀 모형의 시차
- d: 차분 누적의 횟수
- q: 이동평균 모형의 시차
이러한 모수를 설정하는 방법으로는 ACF, PACF가 있다.
ACF
- 시차(lag)에 따른 관측치들 사이의 관련성을 측정하는 함수
- 주어진 시계열의 현재 값이 과거 (y_{t-1}, y_{t-2}, ...., y_{t-n}yt−1,yt−2,....,yt−n) 값과 어떻게 상관되는지 설명함
- ACF plot에서 X축은 상관계수를, y축은 시차수를 나타냄
PACF
- 다른 관측치의 영향력을 배제하고 두 시차의 관측치 간 관련성을 측정하는 함수
- k 이외의 모든 시차를 갖는 관측치(y_{t-1}, y_{t-2}, ...., y_{t-k+1}yt−1,yt−2,....,yt−k+1)의 영향력을 배제한 가운데 특정 두 관측치, y_{t}와 y_{t-k}가 얼마나 관련이 있는지 나타내는 척도
(무슨말이야 이게...)
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(ts_log) # ACF : Autocorrelation 그래프 그리기
plot_pacf(ts_log) # PACF : Partial Autocorrelation 그래프 그리기
plt.show()

ARIMA 모델은 하다가 포기.. 도대체 무슨말인지 전혀 모르겠다... 읽다가 짜증이 치밀어오름
'AIFFEL' 카테고리의 다른 글
| AIFFEL 아이펠 32일차 (0) | 2022.02.16 |
|---|---|
| AIFFEL 아이펠 31일차 (0) | 2022.02.16 |
| AIFFEL 아이펠 29일차 (0) | 2022.02.10 |
| AIFFEL 아이펠 28일차 (0) | 2022.02.10 |
| AIFFEL 아이펠 27일차 (0) | 2022.02.10 |



