
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 재귀함수
- Set
- 기사
- 파이썬
- AI
- 데이터사이언티스트
- 머신러닝
- 데이터사이언스 스쿨
- AIFFEL
- NLP
- Python
- 딕셔너리
- 추천시스템
- numpy
- 딥러닝
- 자연어처리
- 클래스
- 데이터분석
- 스크랩
- 파이썬코딩도장
- 후기
- 아이펠
- 속성
- 함수
- 제로베이스 데이터사이언스
- 코딩도장
- 사이킷런
- 카카오
- 제어문
- TensorFlow
- Today
- Total
뮤트 개발일지
AIFFEL 아이펠 21일차 본문
인물사진을 만들어보자
셸로우 포커스 만들기
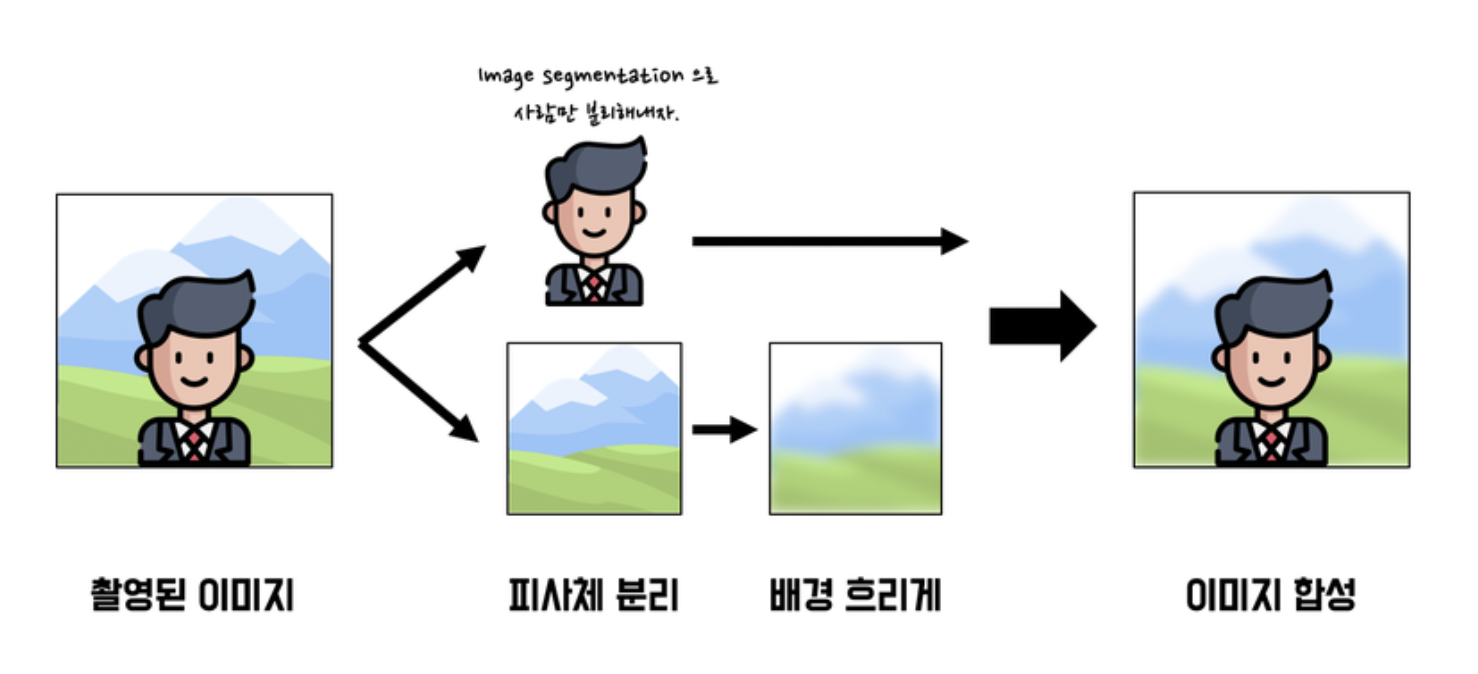
사진 준비하기
import os
# 웹에서 데이터를 다운로드할 때 사용
import urllib
# OpenCV라이브러리, 이미지를 처리할 때 사용
import cv2
import numpy as np
# 시맨틱 세그멘테이션을 사용할 수 있도록 지원하는 라이브러리
from pixellib.semantic import semantic_segmentation
from matplotlib import pyplot as plt# 이미지 불러오기
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/samsuni.jpeg'
img_orig = cv2.imread(img_path)
print(img_orig.shape)
plt.imshow(cv2.cvtColor(img_orig, cv2.COLOR_BGR2RGB))
plt.show()
이미지 추출하기
세그멘테이션: 이미지에서 픽셀 단위로 관심 객체를 추출하는 방법
시맨틱 세그멘테이션: 세그멘테이션 중 우리가 인식하는 세계처럼 물리적 의미 단위로 인식하는 세그멘테이션. 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적 단위로 분류하는 방법
인스턴스 세그멘테이션: 시맨틱 세그멘테이션은 '사람'이라는 추상적인 정보를 이미지에서 추출해 내는 방법. 사람이 누구인지 관계없이 같은 라벨로 표현된다. 인스턴스 세그멘테이션은 사람 개개인별로 다른 라벨을 가지게 한다.
DeepLab 모델 사용
DeepLab에 대한 설명
DeepLab V3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Semantic Segmentation 이미지 분석 task 중 semantic segmentation은 중요한 방법 중 하나입니다. Semantic segmentation은 입력 영상에 주어진 각각의 픽셀에 대해서 class label을 할당하는 것을 목표로 합니다. 주로
blog.lunit.io
모델 불러오기: pixeLib에서 제공
# 저장할 파일 이름을 결정
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
model_file = os.path.join(model_dir, 'deeplabv3_xception_tf_dim_ordering_tf_kernels.h5')
# PixelLib가 제공하는 모델의 url
model_url = 'https://github.com/ayoolaolafenwa/PixelLib/releases/download/1.1/deeplabv3_xception_tf_dim_ordering_tf_kernels.h5'
# 다운로드 시작
urllib.request.urlretrieve(model_url, model_file)
# 모델 생성
model = semantic_segmentation()
model.load_pascalvoc_model(model_file)
# 모델에 이미지 불러오기
segvalues, output = model.segmentAsPascalvoc(img_path)segmentAsPascalvoc(): pascal voc 데이터로 학습된 모델을 이용한다.
* 어떤 데이터를 학습시켰는지 확인하기!
# pascal voc 데이터의 라벨 종류
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
>>> 21# 모델에서 나온 출력값 확인
plt.imshow(output)
plt.show()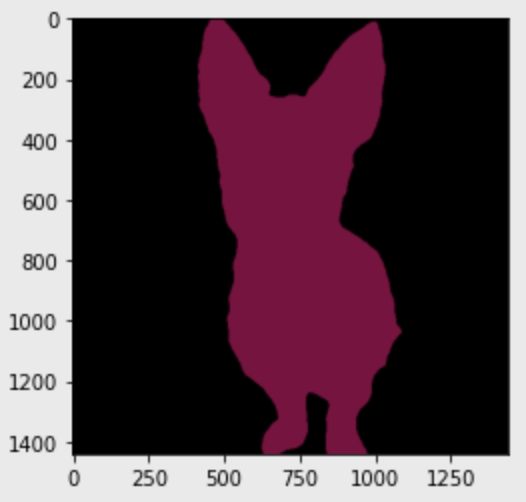
for class_id in segvalues['class_ids']:
print(LABEL_NAMES[class_id])
>>>
background
dogoutput 이미지는 BGR 순서로 배치되어 있다. colormap은 RGB 순서이기 때문에 배치 순서를 바꿔야한다.
# 'dog' 색상 확인
colormap[12]
# 순서 바꾸기
seg_color = (128, 0, 64)
# seg_color 로만 이루어진 마스크 만들기
# output의 픽셀 별로 색상이 seg_color와 같다면 1(True), 다르다면 0(False)이 된다.
seg_map = np.all(output==seg_color, axis=-1)
print(seg_map.shape)
plt.imshow(seg_map, cmap='gray')
plt.show()# 원래 이미지랑 겹쳐보기
img_show = img_orig.copy()
# True과 False인 값을 각각 255과 0으로 바꿔준다
img_mask = seg_map.astype(np.uint8) * 255
# 255와 0을 적당한 색상으로 바꾼다
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
# 원본 이미지와 마스트를 적당히 합친다
# 0.6과 0.4는 두 이미지를 섞는 비율
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.4, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()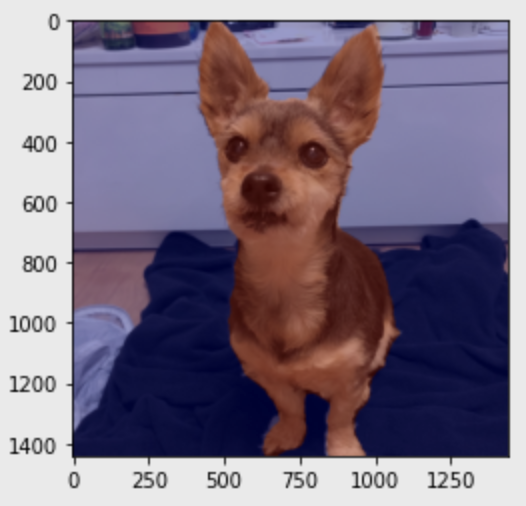
배경 흐리게 하기
# (50,50)은 blurring kernel size
img_orig_blur = cv2.blur(img_orig, (50,50))
plt.imshow(cv2.cvtColor(img_orig_blur, cv2.COLOR_BGR2RGB))
plt.show()# 배경만 추출하기
img_mask_color = cv2.cvtColor(img_mask, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()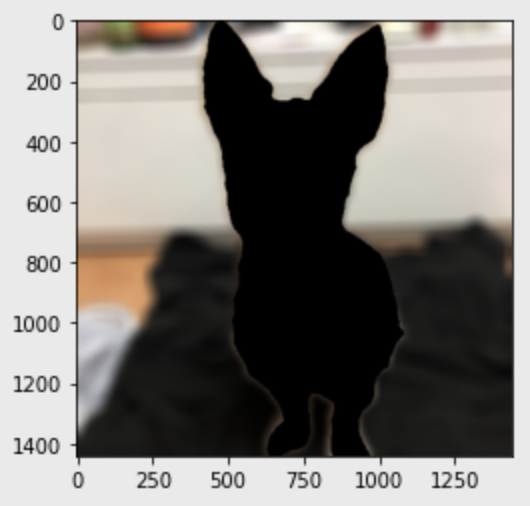
배경과 물체 합치기
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()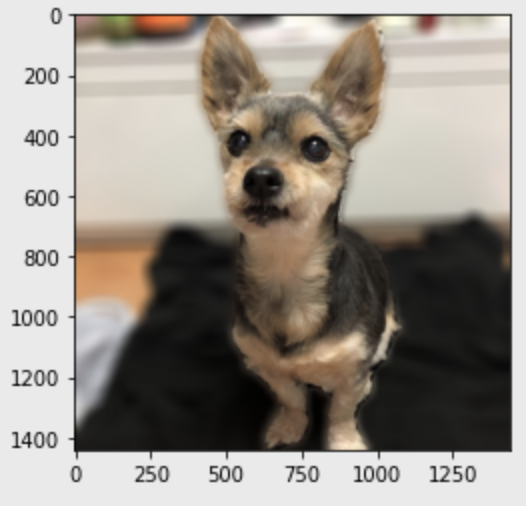
https://github.com/pjk7565/AIFFEL/blob/main/Exploration07/segmentation-Copy1.ipynb
GitHub - pjk7565/AIFFEL
Contribute to pjk7565/AIFFEL development by creating an account on GitHub.
github.com
'AIFFEL' 카테고리의 다른 글
| AIFFEL 아이펠 23일차 (0) | 2022.02.03 |
|---|---|
| AIFFEL 아이펠 22일차 (0) | 2022.01.26 |
| AIFFEL 아이펠 20일차 (0) | 2022.01.25 |
| AIFFEL 아이펠 19일차 (0) | 2022.01.25 |
| AIFFEL 아이펠 18일차 (0) | 2022.01.25 |


